on syntax-highlighting text-similarity
I'd like to share a little tool that I created that I've been playing with. I think now is the time to share it because I believe it has a unique solution to the “how do you chunk up a document” for #LLM #embeddings, which is something @simon@simonwillison.net" title="simon@simonwillison.net">@simon mentioned being an open challenge in his recent blog post.
I've been calling it Semeditor, short for Semantic Editor, available here: https://gist.github.com/player1537/1c23b91b274d2e885be80d5892bac5b7
It can be run with --demo to get the text from the screenshot.
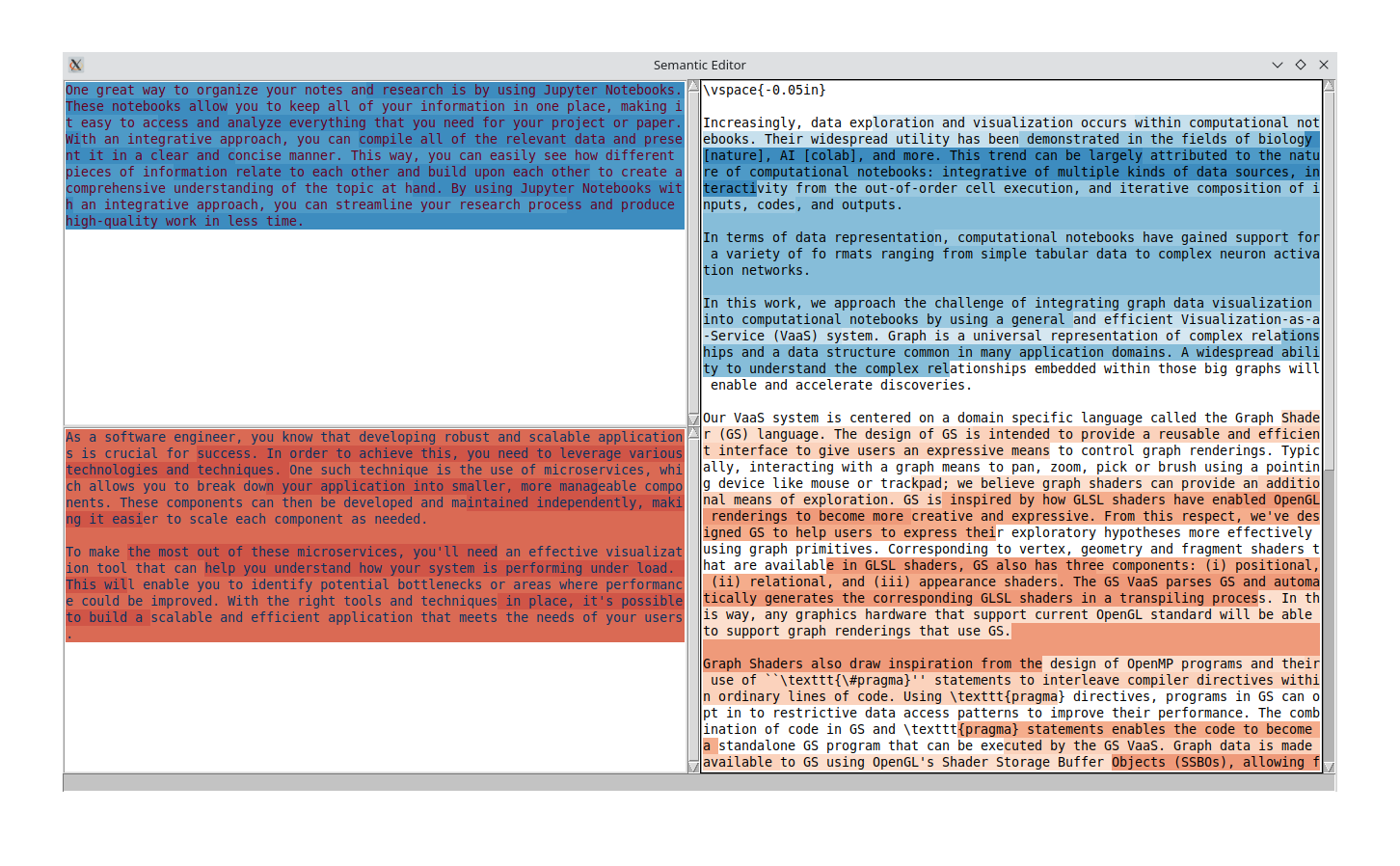
This tool is born out of a need of mine: I'm currently editing an academic paper and I'm in charge of revising the story from one concept (web services) to another concept (jupyter extensions). But that's a tricky thing to quantify: how can one know what the text is actually about?
So, I wanted to create a syntax highlighter that highlights the semantic difference between the meanings of the texts.
Functionally, the tool takes two samples of text (top-left, bottom-left) and finds a way to differentiate those two samples.Then, it applies that same differentation on a third sample of text (right) and highlights accordingly.
For the semantic meaning of the text, I used the smallest model I could find: BAAI/bge-small-en. For differentating the text, I used a Support Vector Machine (SVM) classifier.
Now, for what I feel is the most interesting part of this tool: the chunking.
Since this is running locally on one's computer, I really don't want to constantly recompute the embeddings, especially as I'm intending this to be an editor, so the edits could be early on in the text and that would ruin naive chunking strategies.
Instead, I used an implementation of Content Defined Chunking (CDC) for Python called FastCDC.
The core idea of CDC is to consistently determine chunk boundaries based on the contents of the text. So, in theory, if you edit one part of the text early on, eventually the chunking will re-align itself with previous chunk boundaries.
I believe this works off of a windowed hashing function, so hash(string[i:i+N]) and check if the first few binary digits are zeros, and if so, output a chunk boundary.
You can control the chunking to get arbitrarily small chunks: I use between 32 and 128 chars.
To make each chunk more usable, especially in the face of chunk boundaries cutting words in half, I combine three chunks together to compute the actual embeddings from.
In terms of usability, I've already found this useful, at least marginally. I wanted to flex my tkinter knowledge a bit so I created it as a GUI app and I've found the need to add a couple convenience features. First, repeating the exemplars (left) gives better results. Second, asking an LLM to rephrase helps.
I'm scared of sharing projects like these because I worry they'll either be completely ignored, or worse, looked down upon. Regardless, I'm hoping to overcome that fear by just sharing it anyways.
Especially now, because I feel the techniques within it will become obsolete soon, but I think it's an interesting enough technique that I want to share it before it becomes obsolete. Maybe it will inspire someone, who knows.